AWS SLA: Are you able to keep your availability promise?
Are you offering availability of 99.99% or more to your clients? Bad news, you might not be able to keep your promise!
Recently AWS announced a bunch of new Service Level Agreements (SLA). Therefore, it is now possible to calculate the expected availability of most of the architectures on AWS.

Typically, each SLA contains:
- Service Commitment defines the availability objective (e.g., monthly uptime of at least 99.99%)
- Definitions specifies the used terms. Most importantly defines how to measure the availability of a service.
- Service Credits states how AWS compensates customers affected by missed availability objectives (e.g., 30% service credit).
- Exclusions defines which circumstances are not covered by the service commitment.
Also, it is essential to distinguish between two different availability definitions:
- per period used by EC2, ELB, and RDS.
- per request used by Route 53, S3, Lambda, and DynamoDB.
Generally, each SLA covers a service deployed within multiple Availability Zones within a region.
The following table lists the SLA published by AWS (see * for details).
| Service | SLA | Type |
|---|---|---|
| Route 53 | 100.0% * | request |
| ELB/ALB/NLB | 99.99% * | period of time |
| EC2 | 99.99% * | period of time |
| EBS | 99.99% * | period of time |
| EFS | 99.9% * | period of time |
| ECS | 99.99% * | period of time |
| Fargate | 99.99% * | period of time |
| RDS | 99.95% * | period of time |
| API Gateway | 99.95% * | request |
| Lambda | 99.95% * | request |
| DynamoDB | 99.99% * | request |
| S3 | 99.9% * | request |
| CloudFront | 99.9% * | request |
| Step Functions | 99.9% * | request |
| Cognito | 99.9% * | request |
| Amazon MQ | 99.9% * | period of time |
| Secrets Manager | 99.9% * | request |
| ECR | 99.9% * | request |
| EKS | 99.9% * | period of time |
| Kinesis Video Streams | 99.9% * | request |
| Kinesis Data Firehose | 99.9% * | request |
| Kinesis Data Streams | 99.9% * | request |
| EMR | 99.9% * | request |
So, how to calculate the expected availability of your AWS architecture? To do so, we make two assumptions:
- Whenever one of the services fails, it affects the client.
- There is no dependency between the services. They all fail independently from each other.
In that case, we need to multiply the availability objective of each service. The following figure shows an example of a typical web application running on EC2.
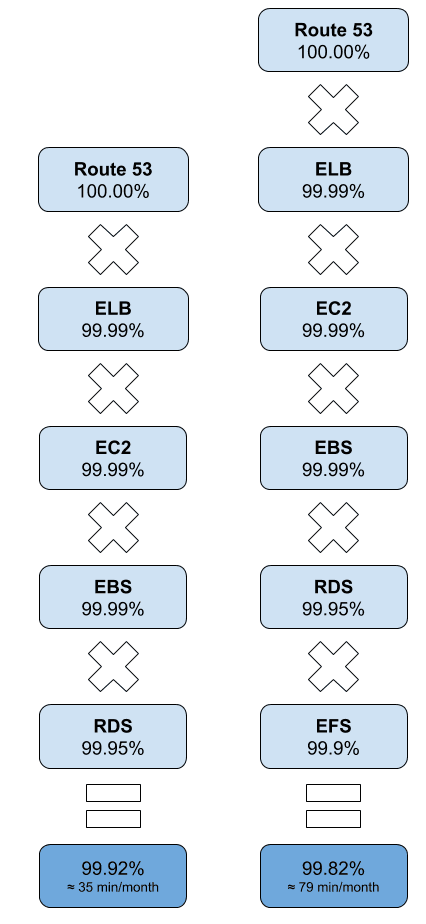
You can use the same approach to calculate the availability for your serverless application as illustrated in the following figure.

The shown examples result in an expected availability of 99.80% to 99.92% depending on the involved services.
Next, calculate the expected availability for your architecture. Please note, that our expected availability calculated for your architecture is pessimistic because our assumptions cover the worst case.
However, keep in mind that the expected availability does only cover failures within your cloud infrastructure. It does not include an error budget for your software or failed deployments, for example.
Are you able to keep your promise?
Are you looking for a way to increase the expected availability of your architecture? Deploy your workload to multiple regions. But be warned, doing so comes with additional complexity caused by the need to synchronize your data between multiple regions.
Andreas Wittig

I’ve been building on AWS since 2012 together with my brother Michael. We are sharing our insights into all things AWS on cloudonaut and have written the book AWS in Action. Besides that, we’re currently working on bucketAV,HyperEnv for GitHub Actions, and marbot.
Here are the contact options for feedback and questions.Further reading
- Article How to become an AWS expert
- Article Eat your own dog food: how AWS leverages Serverless
- Article My mental model of AWS
- Tag ec2
- Tag rds
- Tag serverless