Tweaking RDS database performance and ElastiCache
Tweaking database performance
An RDS database, or a SQL database in general, can only be scaled vertically. To scale a database vertically means to increase the resources of your database but you still have a single database. If the performance of your database becomes insufficient, you must increase the performance of the underlying hardware:
- Faster CPU
- More memory
- Faster storage
Keep in mind that you can’t increase resources without limits. One of the largest RDS database instance types comes with 32 cores and 244 GiB memory. In comparison, an object store like S3 or a NoSQL-database like DynamoDB can be scaled horizontally without limits.
This article, excerpted from chapter 11 and 12 of Amazon Web Services in Action, Second Edition.
Save 37% off [Amazon Web Services in Action, Second Edition](http://bit.ly/amazon-web-services-in-action-2nd-edition) with code `fccwittig` at [manning.com](http://bit.ly/amazon-web-services-in-action-2nd-edition).

Increasing database resources
When you start an RDS database, you choose an instance type. An instance type defines the computing power and memory of a virtual machine (like when you start an EC2 instance). Choosing a bigger instance type increases computing power and memory for RDS databases.
You can change the instance type with the help of the CloudFormation template, the CLI, the Management Console, or AWS SDKs. You may want to increase the instance type if the performance isn’t good enough for you. The following listing shows a CloudFormation snippet to create a MySQL database of type db.m3.large with 2 virtual cores and 7.5 GB memory.
Database: |
Because a database has to read and write data to a disk, I/O performance is important for the database’s overall performance. RDS offers three different types of storage, as you may already know from the block storage service EBS:
- General purpose (SSD)
- Provisioned IOPS (SSD)
- Magnetic
You should choose general purpose (SSD) or even provisioned IOPS (SSD) storage for production workloads. The options are exactly the same as for the block storage service EBS you can use for virtual machines. If you need to guarantee a high level of read or write throughput, you should use the provisioned IOPS (SSD) option. The general purpose (SSD) option offers moderate baseline performance with the ability to burst. The throughput for general purpose (SSD) depends on the initialized storage size. Magnetic storage is an option if you need to store data at a low cost or if you don’t need to access it in a predictable, performant way. The next listing shows how to enable general purpose (SSD) storage with the help of a CloudFormation template.
Database: |
Using read replication to increase read performance
SQL databases can also be scaled horizontally in special circumstances. A database suffering from many read requests can be scaled horizontally by adding additional database instances for read replication. As figure 1 shows, changes to the database are asynchronously replicated to an additional read-only database instance. The read requests can be distributed between the master database and its read-replication databases to increase read throughput.

Tweaking read performance with replication makes sense only if an application generates many read requests and few write requests. Fortunately, most applications read more than they write.
Creating a read-replication database
Amazon RDS supports read replication for MySQL, MariaDB, and PostgreSQL databases. To use read replication, you need to enable automatic backups for your database.
Warning: Starting an RDS read replica will incur charges. See https://aws.amazon.com/rds/pricing/ if you want to find out the current hourly price.
Execute the following command from your local machine to create a read-replication database. Replace the $DBInstanceIdentifier with the value from aws rds describe-db-instances --query "DBInstances[0].DBInstanceIdentifier" --output text.
$ aws rds create-db-instance-read-replica \ |
RDS automatically triggers the following steps in the background:
- Creating a snapshot from the source database, also called the master database
- Launching a new database based on that snapshot
- Activating replication between the master and read-replication databases
- Creating an endpoint for SQL read requests to the read-replication database
After the read-replication database is successfully created, it’s available to answer SQL read requests. The application using the SQL database must support the use of a read-replication database. WordPress, for example, doesn’t support the use of a read replica by default, but you can use a plugin called HyperDB to do this; the configuration is a little tricky, but we’ll skip this part. You can get more information here: https://wordpress.org/plugins/hyperdb/. Creating or deleting a read replica doesn’t affect the availability of the master database.
Using read replication to transfer data to another region
RDS supports read replication between regions for Aurora, MySQL, MariaDB, and PostgreSQL databases. You can replicate your data from the data centers in Northern Virginia to the data centers in Ireland, for example. Three major use cases for this feature are:
- Backing up data to another region for the unlikely case of an outage of a complete region
- Transferring data to another region to be able to answer read requests with lower latency
- Migrating a database to another region
Creating read replication between two regions incurs an additional cost because you have to pay for the transferred data.
Promoting a read replica to a standalone database
If you create a read-replication database to migrate a database from one region to another, or if you need to perform heavy and load-intensive tasks on your database, such as adding an index, it’s helpful to switch your workload from the master database to a read-replication database. The read replica must become the new master database. Promoting read-replication databases to become master databases is possible for Aurora, MySQL, MariaDB, and PostgreSQL databases with RDS.
The following command promotes the read-replication database you created in this section to a standalone master database. Note that the read-replication database will perform a restart and be unavailable for a few minutes:
$ aws rds promote-read-replica --db-instance-identifier awsinaction-db-read |
The RDS database instance named awsinaction-db-read accepts write requests after the transformation from a read-replication database to a master database’s successful.
Caching data in memory: ElastiCache
Imagine a relational database being used for a popular mobile game where players’ scores and ranks are updated and read frequently. The read and write pressure to the database is extremely high, like when ranking scores across millions of players. Mitigating that pressure by scaling the database may help with load but not necessarily the latency or cost. Also, relational databases tend to be more expensive than caching data stores.
A proven solution that many gaming companies employ is using an in-memory data store, such as Redis, for both caching and ranking through player and game metadata. Instead of reading and sorting the leaderboard directly from the relational database, they also store and use an in-memory game leaderboard in Redis commonly using a Redis Sorted Set which sorts the data automatically upon insertion based on the Sorted Set score parameter. The score value may consist of the actual player ranking or player score in the game.
Because the data resides in memory and doesn’t require heavy computation to produce the sort, the retrieval of the information is incredibly fast, leaving little reason to query this information from a relational database. In addition, any other game and player metadata such as player profile, game level information, etc. that requires heavy reads can also be cached within this in-memory layer, freeing their database from heavy read traffic.
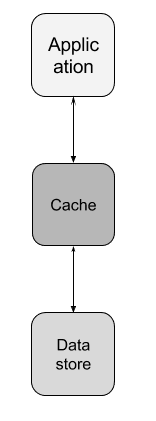
In this solution, both the relational database and in-memory layer store updates to the leaderboard, one serves as the primary database and the other the working and fast processing layer. And for caching data, they may employ a variety of caching techniques to keep the data which is cached fresh, which we’ll review later. Figure 2 shows where the cache sits between your application and the database.
A cache comes with multiple benefits:
- The read traffic can be served from the caching layer which frees resources on your data store e.g. for write requests.
- It also speeds up your application because the caching layer responds faster than your data store.
- You can downsize your data store which can be more expensive than the caching layer.
Most caching layers reside in-memory and this is why they’re fast. The downside is that you can lose the cached data at any time because of a hardware defect or a restart. With Redis, there’s optional failover support. In the event of a node failure, a replica node is elected to be the new primary and already has a copy of the data. Always keep a copy of your data in a primary datastore with disk durability, e.g. like the relational database in the mobile game example.
Depending on your caching strategy you can either populate the cache in real-time or on-demand. In the mobile game example, on demand means that if the leaderboard isn’t in the cache, the application asks the relational database and puts the result into the cache. Any subsequent request to the cache results in a cache hit meaning the data is found. This is true until the duration of the TTL (time to live) value on the cached value expires. Another term for this strategy’s lazy-loading the data from the primary datastore. We could also have a cronjob running in the background that queries the leaderboard from the relation database every minute and puts the result in the cache.
The Lazy Loading Strategy (get data on demand) is implemented like this:
- The application writes data to the data store
- Later, if the application wants to read the data, it makes a request to the caching layer
- The caching layer doesn’t contain the data
- The Application reads from the data store directly and puts the read value into the cache and also returns the value to the client
- Later, if the application wants to read the data again, it makes a request to the caching layer and finds the value
This strategy comes with a problem. What if the data is changed while it’s already in the cache? The cache still contains the old value; setting an appropriate TTL value is critical to ensure cache validity. Let’s say, you apply a TTL for five minutes to your cached data. This means you’re accepting the maximum of five minutes of out of sync data with your primary database. Understanding the frequency of change for the underlying data and the effects of the user experience with producing out of sync data’s the first step of identifying the appropriate TTL value to apply. A common mistake some developers make is assuming that applying a few seconds of a cache TTL makes it not worthwhile of having a cache. Remember within those few seconds, millions of requests can be eliminated from your backend, speeding up your application and reducing the backend database pressure. Performance testing your application with and without your cache along with various caching approaches helps fine tune your implementation.
In summary, the shorter the time to live (TTL) the more load you have on your underlying datastore. The higher the TTL is, the more out of data the data gets.
The Write Through Strategy (cache data upfront) is implemented differently to tackle the synchronization issue:
- The application writes data to the data store and the cache (or the cache is filled asynchronously, e.g. in a cronjob, AWS Lambda function or the application)
- Later, if the application wants to read the data, it makes a request to the caching layer
- The caching layer contains the data
- The value is returned to the client
This strategy comes with a problem. What if the cache isn’t big enough to contain all your data? Caches are in-memory and your data store disk capacity is usually larger than your cache’s memory capacity. When your cache reaches the available memory, it evicts data or stops accepting new data. In both situations, the application doesn’t work anymore. In the gaming app, the global leaderboard always fits into the cache. Imagine a leaderboard is 4 KB in size and the cache has a capacity of 1 GB (1,048,576 KB). But what about team leaderboards? You can only store 262,144 (1,048,576 / 4) leaderboards, and if you have more teams than that, you run into a capacity issue.
Figure 3 compares the two caching strategies.

When evicting data the cache needs to decide which data it should delete. One popular strategy is to evict the least recently used (LRU) data. This means that cached data contains meta information about the time when it was last accessed. In case of a LRU eviction, the data with the smallest timestamp is chosen for eviction.
Caches are usually implemented using key-value stores. A key-value store doesn’t support sophisticated query languages such as SQL. They support to retrieve data based on a key, usually a string, or specialized commands, e.g. to extract sorted data efficiently.
Imagine in your relational database, you’ve a player table for your mobile game. One of the most common queries is SELECT id, nick FROM player ORDER BY score DESC LIMIT 10 to retrieve the top ten players. Luckily, the game is popular. But this comes with a technical challenge. If many players look at the leaderboard, the database becomes busy, which causes high latency or even timeouts. You must come up with a plan to reduce the load of the database. As you already learned, caching can help. What technique should you employ to cache? You have a few options:
One approach you can take with either Memcached or Redis is you can store the result of your SQL query as a String value and the SQL statement as your key name. Instead of using the whole SQL query as the key, you can also hash the string with a hash function like md5 or sha256 to optimize storage and bandwidth (1) as shown in Figure 4. Before the application sends the query to the database, it takes the SQL query as the key to ask the caching layer for data (2). If the cache doesn’t contain data for the key (3), the SQL query sends to the relational database (4). The result (5) is then stored in the cache using the SQL query as the key (6). The next time the application wants to perform the query it asks the caching layer (7) which now contains the cached table (8).
To implement caching, you only need to know the key of the cached item. This can be a SQL query, a filename, a URL, or a user id. You take the key and ask the cache for a result. If no result is found, you make a second call to the underlying datastore who knows the truth.

With Redis, you also have other options of storing the data in a variety of other data structures such as a Redis SortedSet. If the data was stored in a Redis SortedSet, retrieving the ranked data’s efficient. You could store players and their scores and sort by the score. An equivalent command to the SQL query is:
ZREVRANGE "player-scores" 0 9 |
This returns the ten players in a Sorted Set named “player-scores” ordered by highest to lowest.
The two most popular implementations of in-memory key-value stores are Memcached and Redis. Table 1 compares their features.
| Memcached | Redis | |
|---|---|---|
| Data types | simple | complex |
| Data manipulation commands | 12 | 125 |
| Server-side scripting | no | yes (Lua) |
| Transactions | no | yes |
| Multi-threaded | yes | no |
Amazon ElastiCache offers managed Memcached and Redis clusters. Managed includes:
- Installation: AWS installs the software for you and has enhanced the underlying engines
- Administration: AWS administers Memcached/Redis for you and provides you means to configure your cluster through parameter groups. AWS also detects and automates failovers (Redis only)
- Monitoring: AWS publishes metrics to CloudWatch for you
- Patching: AWS performs security upgrades in a customizable time window
- Backups: AWS optionally backs up your data in a customizable time window (Redis only)
- Replication: AWS optionally sets up replication (Redis only)
Learn more
Do you want to learn more? Check out Amazon Web Services in Action, Second Edition with chapters about RDS and ElastiCache going into more details.
Michael Wittig

I’ve been building on AWS since 2012 together with my brother Andreas. We are sharing our insights into all things AWS on cloudonaut and have written the book AWS in Action. Besides that, we’re currently working on bucketAV, attachmentAV, HyperEnv, and marbot.
Here are the contact options for feedback and questions.Further reading
- Article Amazon Web Services in Action Second Edition is in the works
- Article Introducing AWS Lambda
- Article Send CloudWatch Alarms to Slack with AWS Lambda
- Article Passwordless database authentication for AWS Lambda
- Article Engaging your users with AWS Step Functions
- Article Lessons learned: Serverless Chatbot architecture for marbot
- Tag rds
- Tag elasticache